
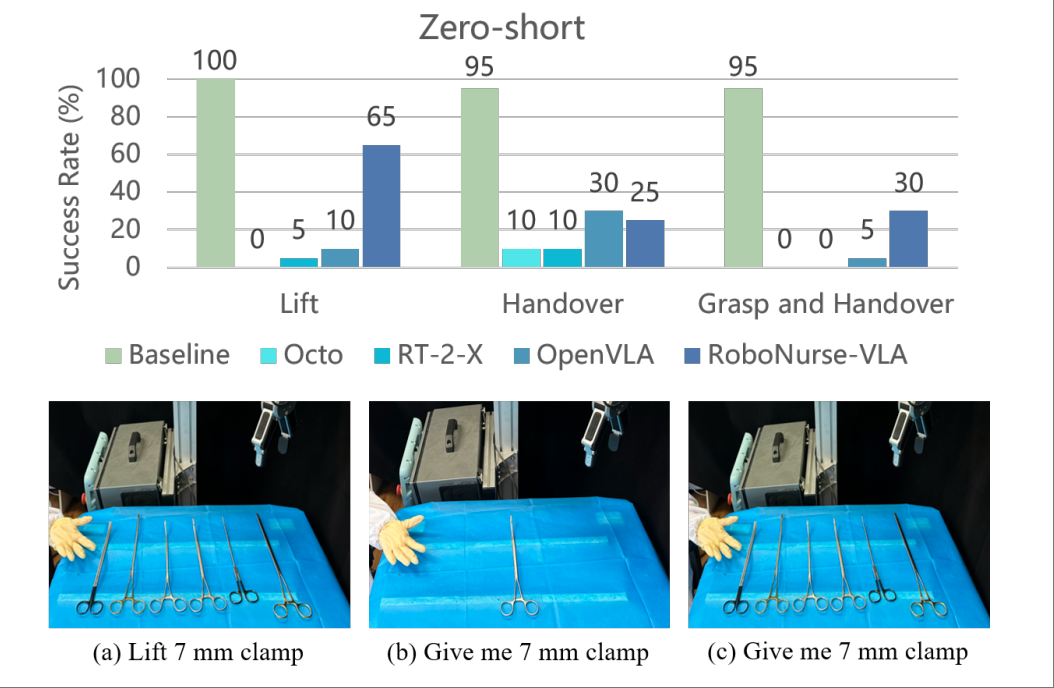
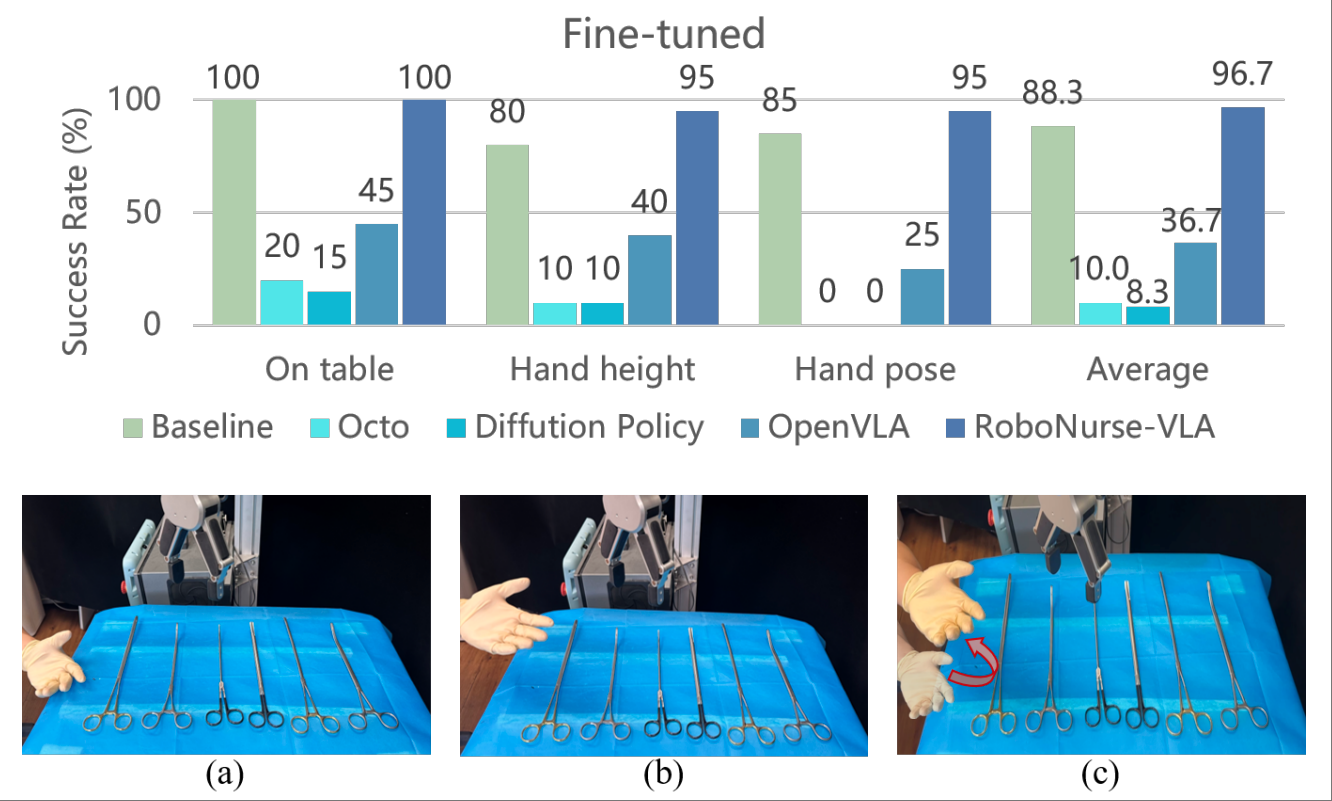
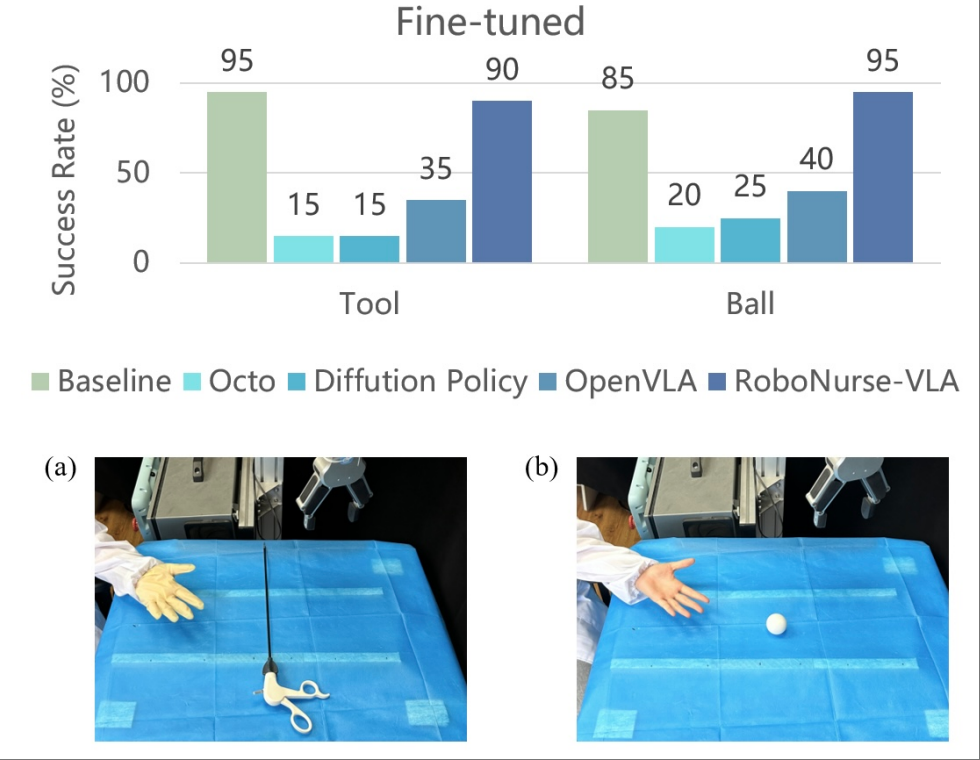
We introduce a novel robotic scrub nurse system, RoboNurse-VLA, built on a Vision- Language-Action (VLA) model by integrating the Segment Anything Model 2 (SAM 2) and the Llama 2 language model. The proposed RoboNurse-VLA system enables highly precise grasping and handover of surgical instruments in real-time based on voice commands from the surgeon. Leveraging state- of-the-art vision and language models, the system can address key challenges for object detection, pose optimization, and the handling of complex and difficult-to-grasp instruments. Through extensive evaluations, RoboNurse-VLA demonstrates superior performance compared to existing models, achieving high success rates in surgical instrument handovers, even with unseen tools and challenging items. This work presents a significant step forward in autonomous surgical assistance, showcasing the potential of integrating VLA models for real- world medical applications.
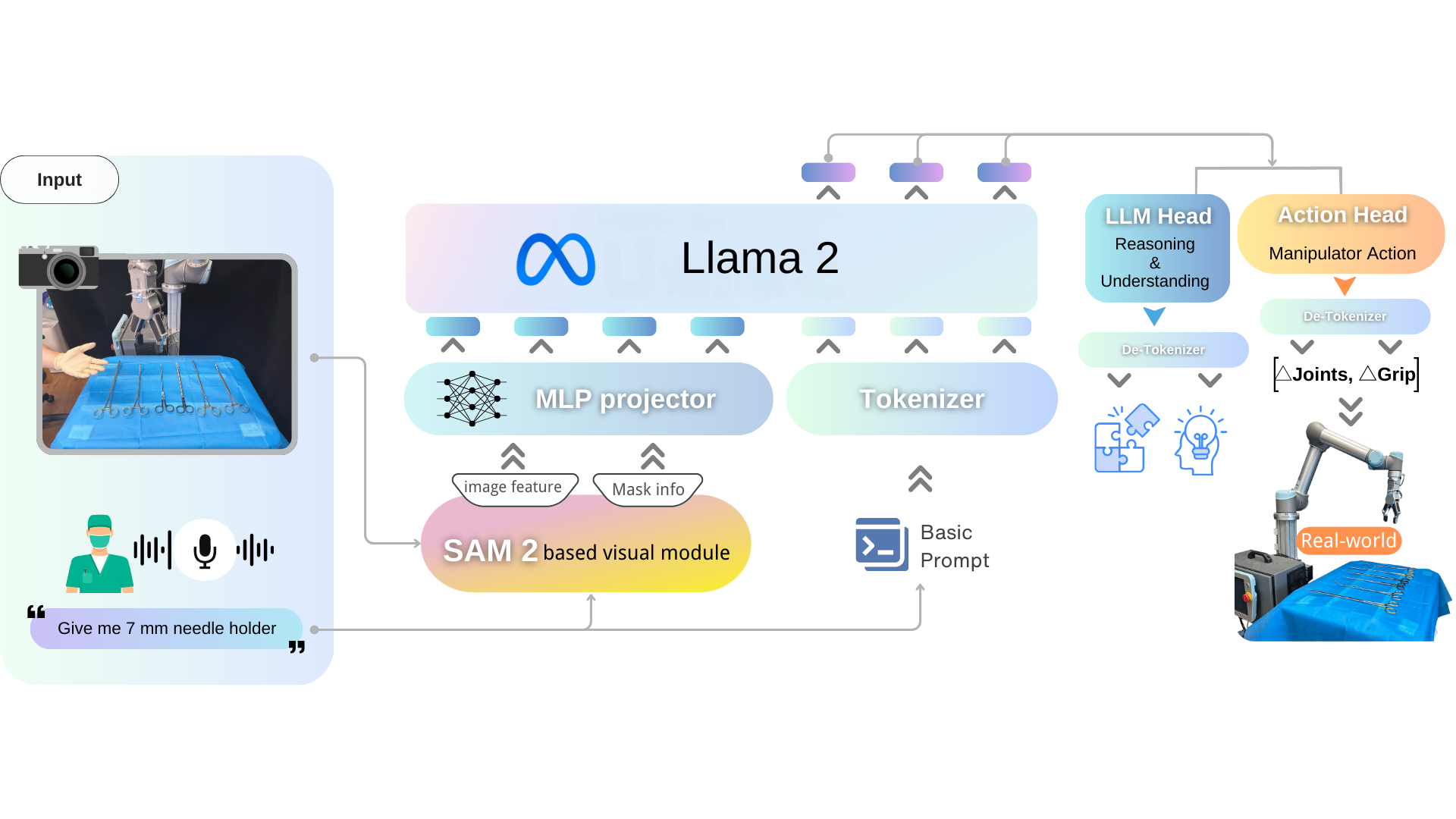
Overview of RoboNurse-VLA: RoboNurse-VLA model architecture. Given an image observation and a speech instruction, the model predicts robot control actions. The architecture consists of three key components: (1) a SAM 2 based vision module, (2) a projector that maps visual features to the language embedding space, and (3) the pretrained Llama 2 7B-parameter LLM in OpenVLA.
@misc{li2024robonursevlaroboticscrubnurse,
title={RoboNurse-VLA: Robotic Scrub Nurse System based on Vision-Language-Action Model},
author={Shunlei Li and Jin Wang and Rui Dai and Wanyu Ma and Wing Yin Ng and Yingbai Hu and Zheng Li},
year={2024},
eprint={2409.19590},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2409.19590},
}